What is Spring Cloud Data Flow?
The official documentation describes it thusly:
Spring Cloud Data Flow is a toolkit to build real-time data integration and data processing pipelines by establishing message flows between Spring Boot applications that could be deployed on top of different runtimes.
Pipelines consist of Spring Boot apps, built using the Spring Cloud Stream or Spring Cloud Task microservice frameworks.
The Data Flow Server provides interface to compose and deploy pipelines onto multiple Cloud platform Using : DSLs, UI Designer, Steam and Task Administration UI.
The Spring Cloud Data Flow server uses Spring Cloud Deployer, to deploy pipelines onto modern runtimes such as Cloud Foundry, Kubernetes, Apache Mesos or Apache YARN.
Runtime platform for managing the lifecycle of Spring Cloud Stream/Task applications. You write your app, then register your application with the running SCDF server (either as a Docker Container, or using Maven coordinates) and then SCDF allows you to define streams that include your application, and manages deploying the application to the underlying platform when a Stream is deployed.
based on Spring Integration; reuses much of the terminology and core concepts of a pipe-and-filter architecture. Conceptually you have data Sources, data Processors, and data Sink. These components communicate by passing Messagesacross Channels managed by a messaging middleware. Apache Kafka and RabbitMQ are supported out-of-the-box but binders could be written for other middlewares.
Sprig Cloud Data Flow Server offers specific set of features that can be enabled/disabled when launching. These features include all the lifecycle operations and REST endpoints (server and client implementations, including the shell and the UI) for:
- Streams
- Tasks
- Analytics
- Skipper
- Task Scheduler
Enables launching of arbitrary short-lived Spring Boot applications. Integrates directly with Spring Batch, so while it’s definitely an oversimplification, you can sort of think of this as a “Spring Cloud Batch”.
SPI for managing deployment of Spring Boot applications to various platforms (Local, Kubernetes, Mesos, Yarn etc.)
Provides ability to define and deploy Packages to a variety of different Platforms. A Package is a manifest file in yaml that defines what should be deployed (perhaps a single spring boot app, or a group of applications). A Platform is where the application actually runs (e.g. Kubernetes). Leverages Spring Cloud Deployer to deploy packages to platforms.
The supported platforms are:
- Cloud Foundry
- Kubernetes
- Local Server
The local server is supported in production for Task deployment as a replacement for the Spring Batch Admin project. The local server is not supported in production for Stream deployments.
Comparison to Other Platform Architectures
Spring Cloud Data Flow’s architectural style is different than other Stream and Batch processing platforms. For example in Apache Spark, Apache Flink, and Google Cloud Dataflow, applications run on a dedicated compute engine cluster. The nature of the compute engine gives these platforms a richer environment for performing complex calculations on the data as compared to Spring Cloud Data Flow, but it introduces the complexity of another execution environment that is often not needed when creating data-centric applications.
Getting Started with Docker Compose
Here are two ways to get started. The quickest is to download the Spring Cloud Data Flow Local-Server's Docker Compose artifact.
$ wget https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v1.7.3.RELEASE/spring-cloud-dataflow-server-local/docker-compose.yml
In the directory where you downloaded docker-compose.yml, start the system SCDF, as follows:
$ export DATAFLOW_VERSION=1.7.3.RELEASE
$ docker-compose upLaunch the Spring Cloud Data Flow Dashboard at http://localhost:9393/dashboard.
Deploy and test a Stream
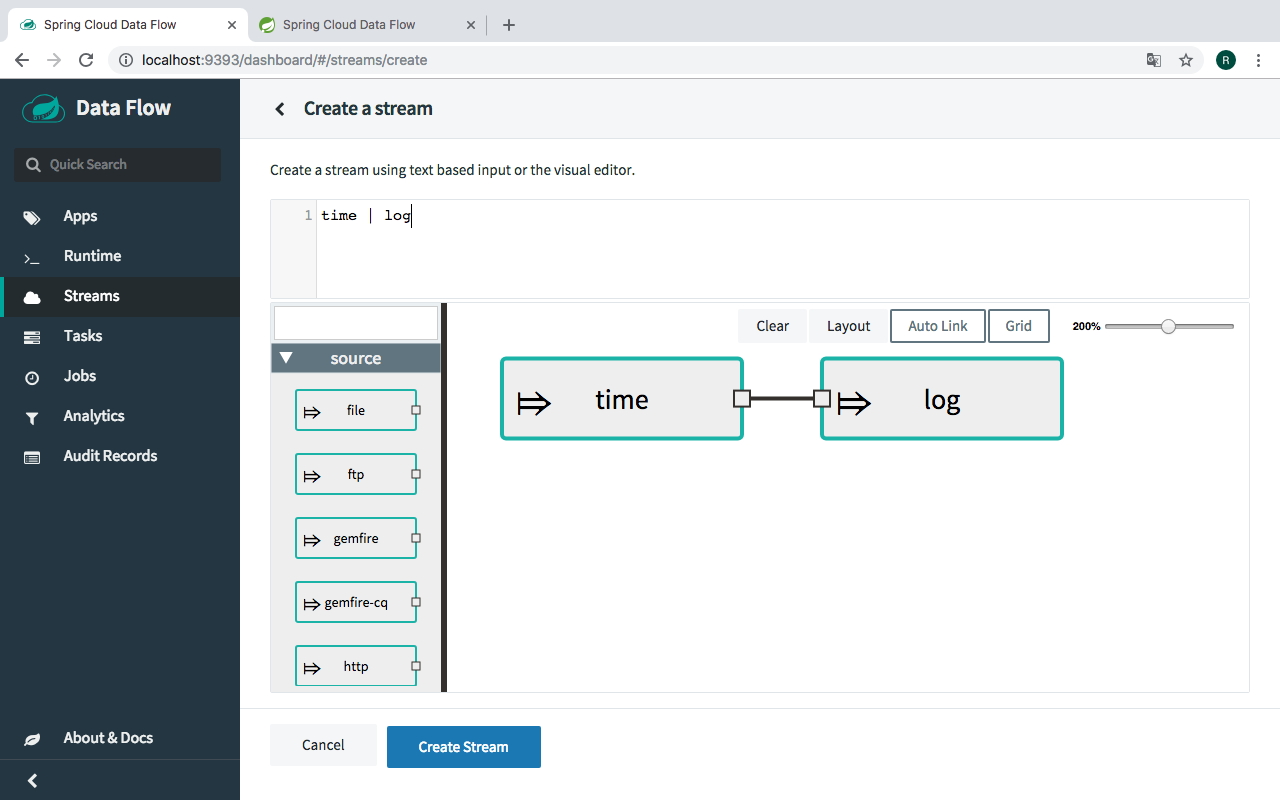
To create a stream, first navigate to the "Streams" menu link then click the "Create Stream" link. Enter time | log into the "Create Stream" text area then click the "CREATE STREAM" button. Enter "ticktock" for the stream name and click the "Deploy Stream(s) checkbox as show in the following image:
See the visual representation :
Now we deploy the Stream :
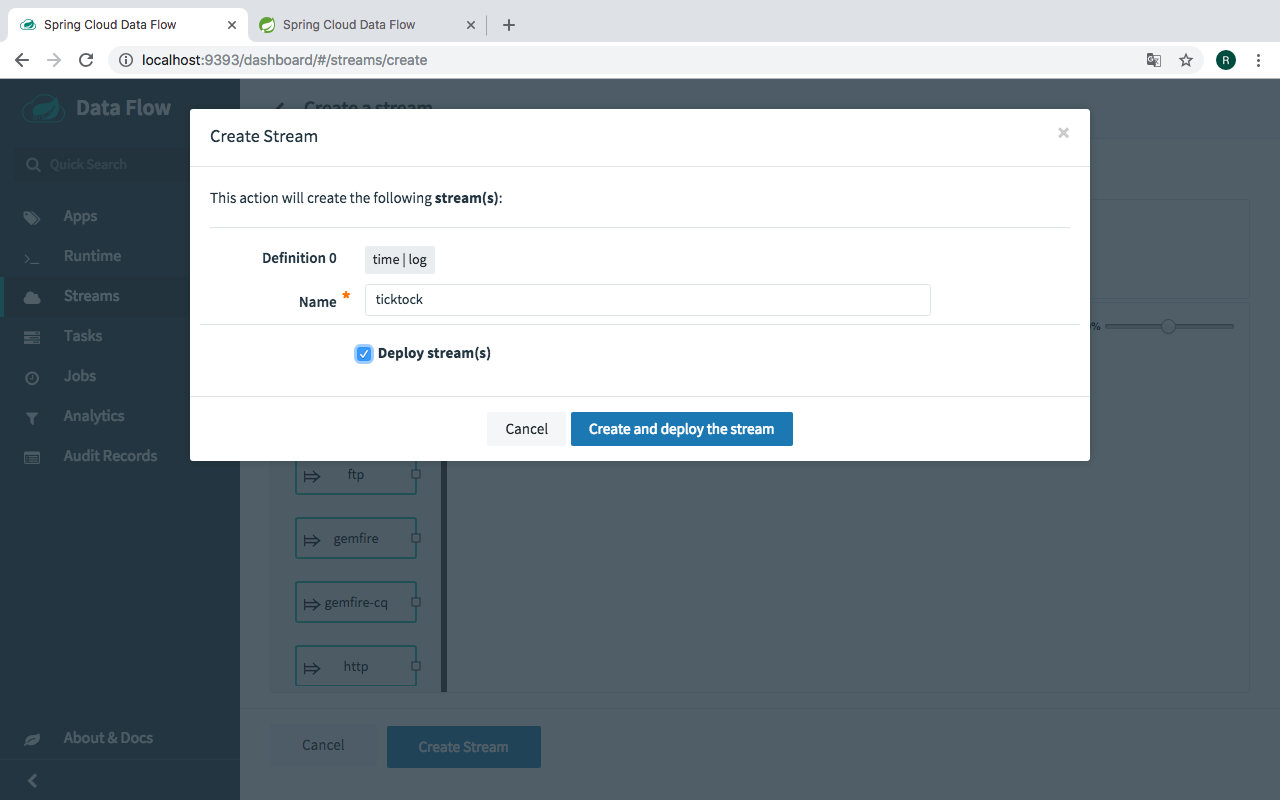
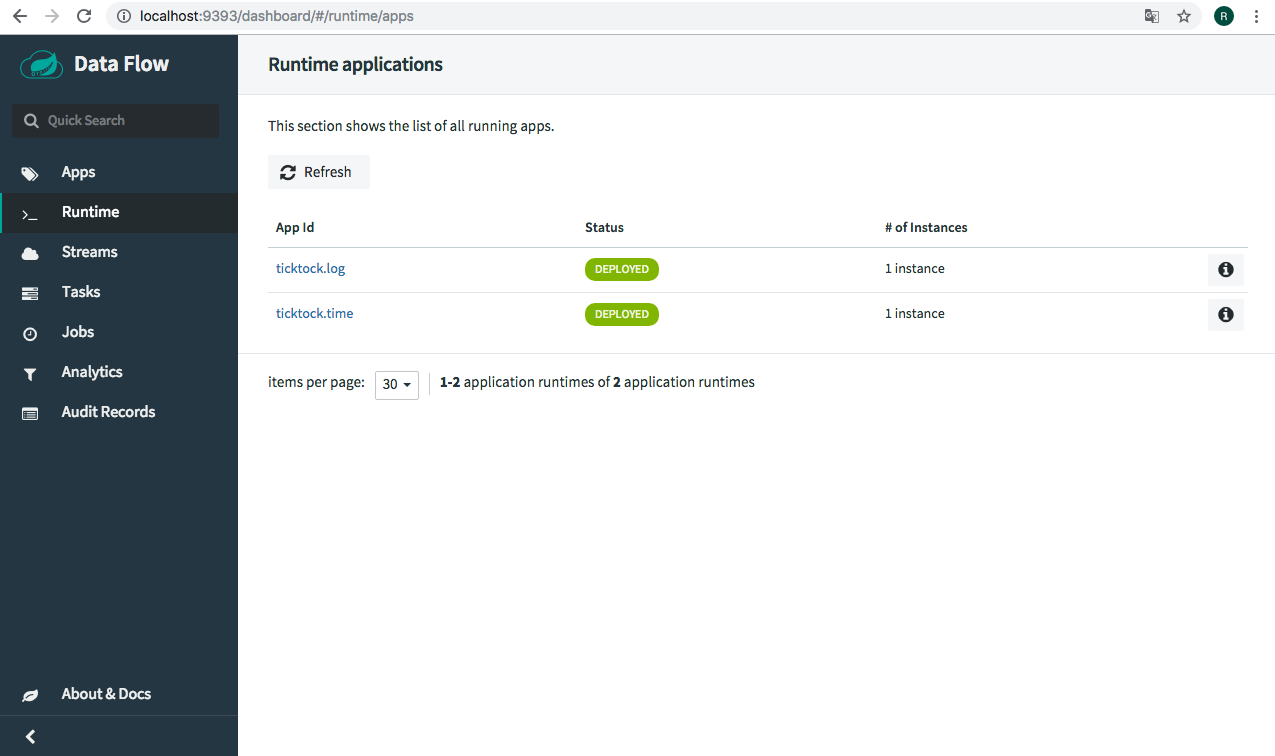
Once the ‘ticktock’ stream is deployed, you will notice two stream-apps (ticktock.log and ticktock.time) under the "Runtime" tab. Click the i icon of the 'ticktock.log' app to copy the path of the streamed logs.
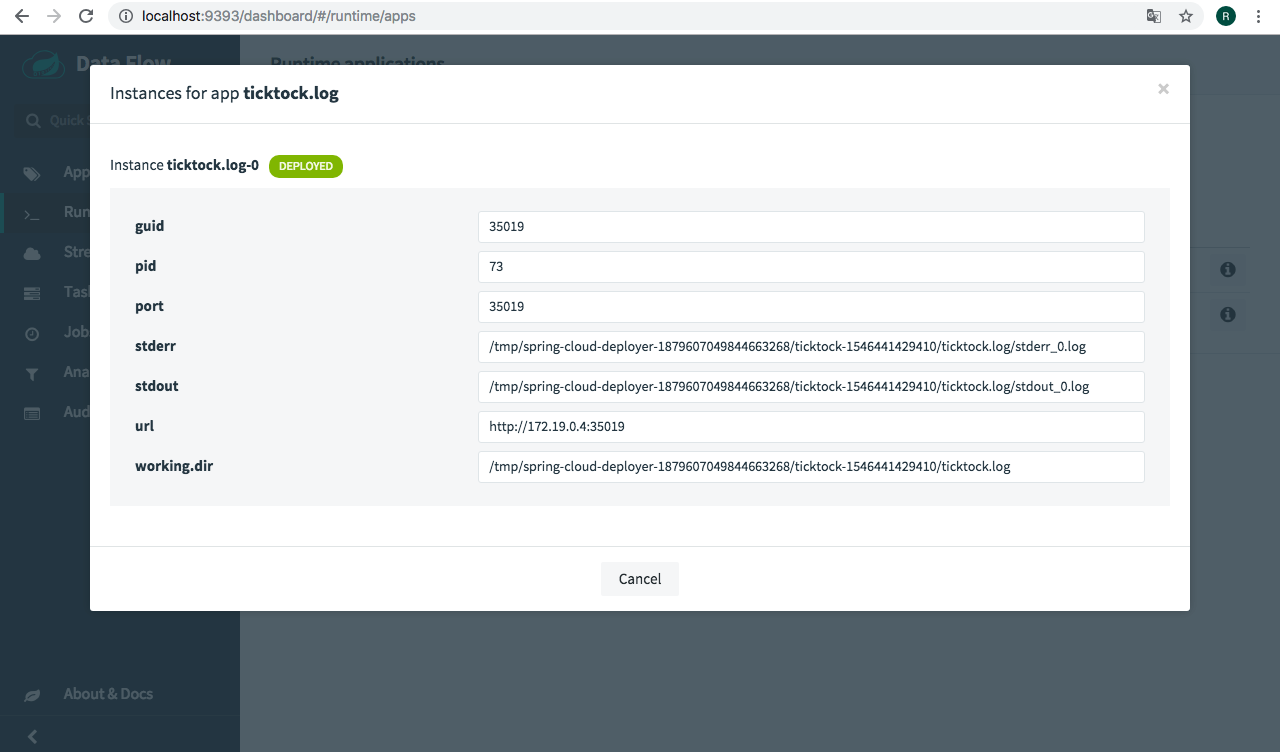
To verify the deployed stream and the results, copy the path in the "stdout" text box from the dashboard. From another terminal-console type:
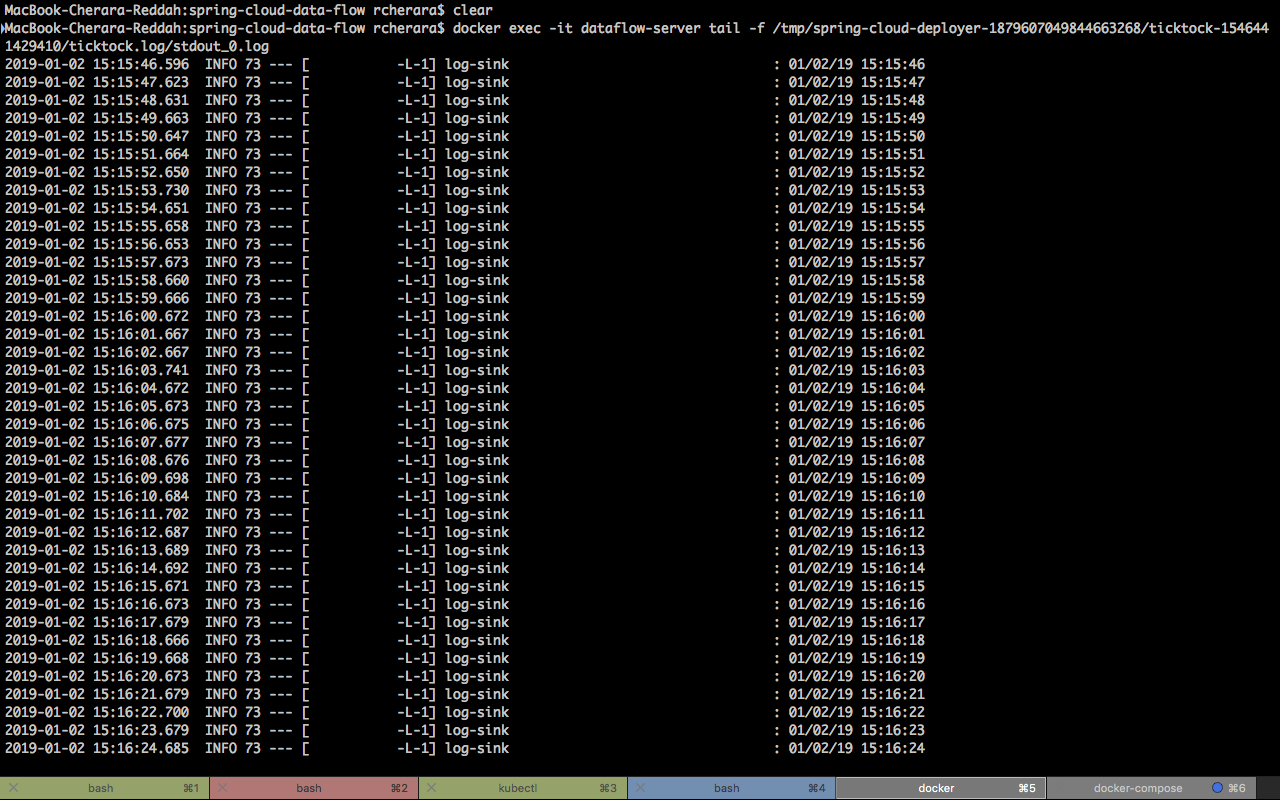
$ docker exec -it dataflow-server tail -f /tmp/spring-cloud-deployer-1879607049844663268/ticktock-1546441429410/ticktock.log/stdout_0.logWe’ll connect the time application source, which generates a timestamp every 1 second, into the log application sync which receives data and writes it to a log file.
We could define this programmatically in java, declaratively via the UI, or even visually in the UI by dragging and dropping the desired components, orvia the CLI using the Stream DSL.
To destroy the Quick Start environment, in another console from where the docker-compose.yml is located, type as follows:
$ docker-compose down